How do we know if we can run terraform apply to our infrastructure without negatively affecting critical business
applications? We can run terraform validate and terraform plan to check our configuration, but will that be enough?
Whether we've updated some HashiCorp Terraform configuration or a new version of a module, we want to catch errors
quickly before we apply any changes to production infrastructure.
In this post, We will discuss some testing strategies for HashiCorp Terraform configuration and modules so that we can
terraform apply with greater confidence.
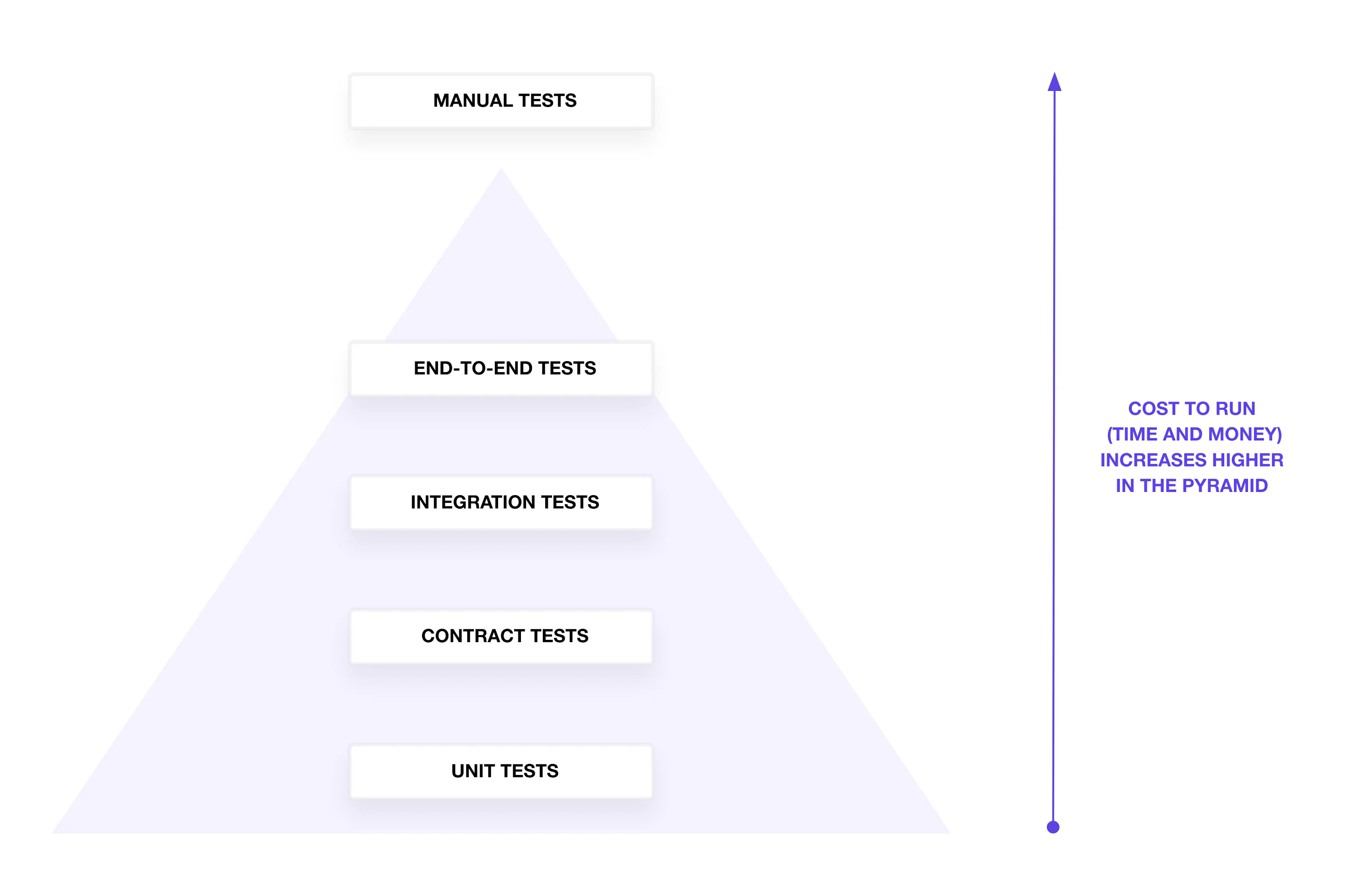
In theory, we might decide to align our infrastructure testing strategy with the test pyramid, which groups tests by
type, scope, and granularity. The testing pyramid suggests that we write fewer tests in the categories at the top of the
pyramid, and more at the bottom. Those on the pyramid take more time to run and cost more due to the higher number of
resources we have to configure and create.
In reality, our tests may not perfectly align with the pyramid shape. The pyramid offers a common framework to describe
what scope a test can cover to verify configuration and infrastructure resources. We'll start at the bottom of the
pyramid with unit tests and work the way up the pyramid to end-to-end tests.
note
hashistack does not merit any manual testing; so it is not discussed here
While not on the test pyramid, we often encounter tests to verify the hygiene of your Terraform configuration. Use
terraform fmt -check and terraform validate to format and validate the correctness of our Terraform configuration.
When we collaborate on Terraform, we may consider testing the Terraform configuration for a set of standards and best
practices. Build or use a linting tool to analyze our Terraform configuration for specific best practices and patterns.
For example, a linter can verify that our teammate defines a Terraform variable for an instance type instead of
hard-coding the value.
At the bottom of the pyramid, unit tests verify individual resources and configurations for expected values. They should
answer the question, “Does my configuration or plan contain the correct metadata?” Traditionally, unit tests should run
independently, without external resources or API calls.
Principal Open Source Engineer at NodeSource and Node.js
Supply chain attacks are not something new; we have heard about them extensively, and the maximum we can do is mitigate
them as best as we can. However, it is crucial to acknowledge that these types of attacks will always exist. With that
in mind, it is important to understand all the attack vectors and take the necessary steps to secure our environment.
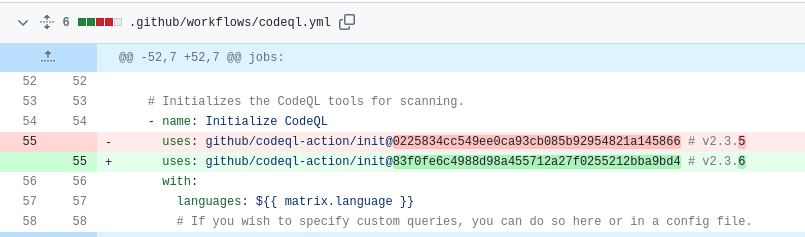
One of the initiatives planned by the Node.js Security WG (Working Group) for 2023 is to enhance the OSSF Scorecard.
This task requires changing all Node.js actions to be pinned by commit-hash. The reason for this approach is quite
simple: commit-hash provides immutability, unlike tags which do not.
For instance, it is quite common to include the following action as part of our application's CI pipeline:
Many developers rely on tools like Dependabot or Renovatebot to ensure that these actions stay up-to-date. However,
using the release tag can pose a risk to our environment.
Looking at a Scenario Where a Malicious Actor Gets Control
Let's consider a scenario where a malicious actor gains control over the actions/checkout package. This compromised
package can now potentially manipulate the entire CI process. It can access environment variables used by other jobs,
write to a shared directory that subsequent jobs process, make remote calls, inject malicious code into the production
binary, and perform other malicious activities
What many developers assume is that once they pin an action using a release tag, such as v3.5.2, they are safe because
any new changes would require a new release. However, this assumption is fundamentally incorrect. Release tags are
mutable, and a malicious actor can override them. To illustrate this point, I have created two repositories for
educational purposes:
bad-action - This repository contains a GitHub action that simulates
someone taking over the package.
using-bad-action - This repository demonstrates a project that
utilizes the aforementioned action, as the name suggests.
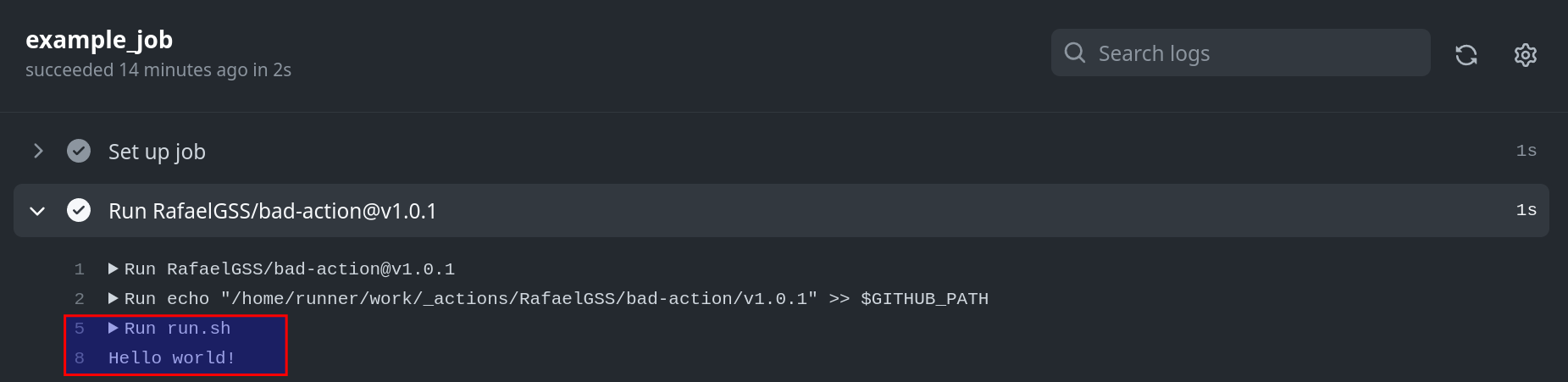
In the .github/workflows/main.yml file of the latter repository, the bad-action is being used in version v1.0.1:
on: workflow_dispatch: jobs: example_job: runs-on: ubuntu-latest steps: -uses: RafaelGSS/bad-action@v1.0.1
For this practical example, workflow_dispatch will be used, but the same applies to on: [push, pull_request]
processes and so on.
As a result, when the action is executed, it prints “Hello world” in the console.
Now, let's consider the scenario where a bad actor takes over the repository and modifies the "Hello world" message to
"Hello darkness my old friend" without creating a new release. Instead, the actor overrides the existing v1.0.1 release
using the following commands:
echo"echo \"Hello darkness my old friend\""> run.sh gitadd run.sh git commit -m"dangerous commit" git push origin :refs/tags/v1.0.1 git tag -fa v1.0.1 git push origin main --tags
Consequently, if the action is executed again without any changes made to the source code, it will print "Hello darkness
my old friend". This demonstrates how our environment can be exploited by manipulating release tags.
Pinning an action to a full-length commit SHA is currently the only method to ensure the use of an action as an
immutable release.
Quoting the OSSF Scorecard
Pinned dependencies help reduce various security risks:
They guarantee that checking and deployment are performed with the same software, minimizing deployment risks,
simplifying debugging, and enabling reproducibility.
They can help mitigate compromised dependencies from compromising the project's security. By evaluating the pinned
dependency and being confident that it is not compromised, we can prevent the use of a later version that may be
compromised.
Pinned dependencies are a way to counter dependency confusion (or substitution) attacks. In these attacks, an
application uses multiple feeds to acquire software packages (a “hybrid configuration”), and attackers trick the user
into using a malicious package from an unexpected feed.
With that in mind, fixing or securing the action is a straightforward process:
There are open-source tools like StepSecurity that can assist us in addressing these
concerns. It generates automated pull requests for our codebase based on the configuration specified on their website.
Being a strong proponent of Immutable Infrastructure, [hashistack] is constantly pushing the limits of its ability
in various use cases, one of which is the Configuration Management
Traditional configuration management includes Chef, Puppet, and Ansible. They all assume mutable infrastructure being
present. For example, Chef has a major component responsible for jumping into a VM, checking if config has been mutated
before apply any operations.
With the adoption of Immutable infrastructure, we initially stored and managed our configuration, such as SSL
certificate or AWS SECRET ACCESS KEY directly in GitHub Secrets. This has the disadvantage of not being able to see
their values after creation, making it very hard to manage.
Then we moved to a centralized runbook, where everything can easily be seen and modified by authorized team members. In
this approache, CI/CD server will pull down the entire runbook and simply pick up the config files. This, however,
exposed a great security risk because illegal usage could simply leak any credentials to public by cating that
credential file out
So the problem, or what [hashistack] is trying to solve here, is
being able to keep credentials, whether it's string values or values stored in files, secure, and
allowing team member to easily manage those credentials
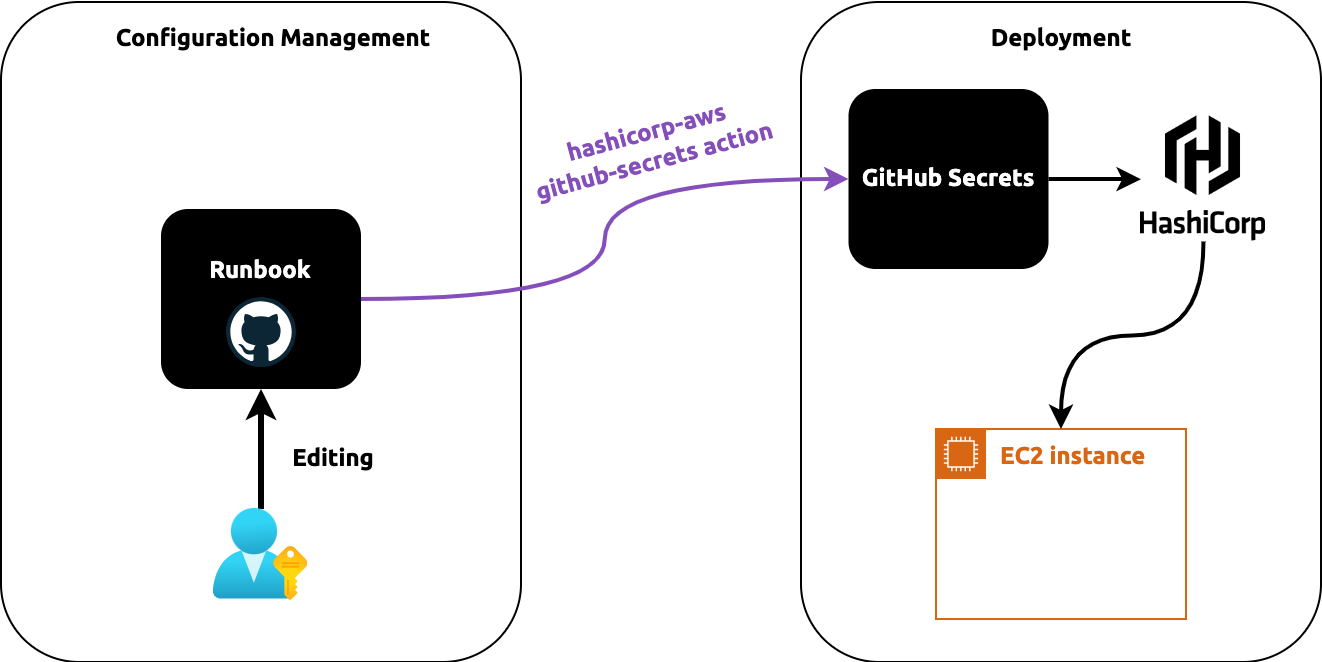
So this brought us to the alternative way of thinking about Configuration Management in Immutable Infrastructure, which
is depicted below:
We still need GitHub Secrets because our tech dev has a deep integratin with it and that's the most secure way to pass
our organization credentials around.
In addition, we will also keep runbook for config management. The runbook will be hosted separately, not in GitHub
Secrets.
info
Runbooks was used in Yahoo that keeps all DevOps credentials in a dedicated GitHub private repo. It's been proven to
be an effective way to manage and share a software configurations within a team.
hashistack's github-secret now comes into play to bridge the gap between two componet.
A matrix strategy lets you use variables in a single job definition to automatically create multiple job runs that are
based on the combinations of the variables. For example, you can use a matrix strategy to test your code in multiple
versions of a language or on multiple operating systems.
OpenSSL is a powerful cryptography toolkit. Many of us have already used OpenSSL for creating RSA Private Keys or CSR
(Certificate Signing Request). However, did you know that we can use OpenSSL to benchmark our computer speed or that we
can also encrypt files or messages? This post will provide you with some simple to follow tips on how to encrypt
messages and files using OpenSSL.
On every push to GitHub, GitHub Action can
auto-trigger the docker image build and push to Docker Hub. We will be able to see that each
push results in a usable image, which enhances the quality of a docker image a lot.
Node Version Manager is a tool that helps us manage Node versions and is a convenient
way to install Node. Think of it as npm or Yarn that helps manage Node packages, but instead of packages, NVM manages
Node versions.
This also means you can install multiple Node versions onto your machine at the same time and switch among them if
needed.
Jenkins is an open-source automation server that integrates with a number of AWS Services, including: AWS CodeCommit,
AWS CodeDeploy, Amazon EC2 Spot, and Amazon EC2 Fleet. We can use Amazon Elastic Compute Cloud (Amazon EC2) to deploy a
Jenkins application on AWS.
This post documents the process of deploying a Jenkins application. We will launch an EC2 instance, install Jenkins on
that instance, and configure Jenkins to automatically spin up Jenkins agents if build abilities need to be augmented
on the instance.